
공공데이터를 활용하는 방법에는
1. 공공데이터 사이트에서 파일을 다운받아 파싱
2. 온라인에서 바로 파싱
이번에는 1. 다운받은 파일을 파싱하는 법을 알아보자.

0. 파일 넣기
- 우선 다운받은 파일을 프로젝트의
src/webapp/WEB-INF 에 파일을 만들어서 넣어준다.
commands.properties
- url=핸들러 주소
- url은 인식하기 편하게 지정해준다. url로 불러올 핸들러 주소만 명확하다면 오케이.
/csv/load.do=handler.CsvHandler
/json/load.do=handler.JsonHandler
/xml/load.do=handler.XmlHandler
index
- commands.properties에 적은 url을 적어준다.
- url로 불러올 클래스가 핸들러 클래스이기 때문에 현 프로젝트 주소를 반영하는 ${pageContext.request.contextPath} 꼭 적어주기.
- jsp로의 이동은 필요 없다~
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>공공데이터 활용</h3>
<a href="${pageContext.request.contextPath}/csv/load.do">csv 데이터 확인</a><br/>
<a href="${pageContext.request.contextPath}/json/load.do">json 데이터 확인</a><br/>
<a href="${pageContext.request.contextPath}/xml/load.do">xml 데이터 확인</a><br/>
</body>
</html>
1. CSV 파일
- 엑셀 형태의 파일.
- ","로 값이 나눠져 있음.
- 엔터(\n)로 한 객체의 정보가 나뉜다.



- 년월, 요일, 상_하행, 열차번호 등 같은 양식으로 여러 값이 들어있으므로 루프문을 돌릴 필요가 있다.
--> 루프 문 돌려 리스트에 담을 때 한 줄 당 Vo에 넣어 리스트에 넣으면 jsp에서 출력 루프문 돌릴 때 좋다.
==> VO 생성
public class Vo {
private String arg1;
private String arg2;
private String arg3;
private String arg4;
private String arg5;
private String arg6;
private String arg7;
private String arg8;
private String arg9;
private String arg10;
private String arg11;
private String arg12;
}
- Handler interface를 상속받은 Handler 클래스를 생성한다. -- 여기서 csv 파일을 파싱해서 jsp 페이지로 데이터를 전송할 것.
String path = request.getServletContext().getRealPath("/WEB-INF/files/a_utf8.csv");
FileReader fr = new FileReader(path);
char[] buf = new char[10000];
fr.read(buf);
String str = new String(buf);
String[] data = str.split("\n");
String[] titles = data[0].split(",");
ArrayList<Vo> list = new ArrayList<>();
for (int i = 1; i < data.length; i++) {
String[] vals = data[i].split(",");
if(vals.length<12) {
continue;
}
list.add(new Vo(vals[0], vals[1], vals[2], vals[3], vals[4], vals[5],
vals[6], vals[7], vals[8], vals[9], vals[10], vals[11]));
}
request.setAttribute("titles", titles);
request.setAttribute("list", list);
fr.close();
return "/csv/list.jsp";
(1) 파라메터에 담은 경로를 웹에서 사용하는 실제 경로로 반환해 String path에 담는다.
--- getServletContext() : 서블릿 클래스와 서블릿 컨테이너(톰캣) 간 통신을 위한 메소드들을 정의해둔 클래스
--- getRealPath() : getServletContext의 메서드 중 하나. 주어진 디렉토리(폴더)의 실제 실행되는 서버상의 주소를 절대경로로 알려줌.
(2) csv 파일은 문자 타입이므로 Filereader로 스트림을 생성한다. -- 파일 읽어들일 준비.
(3) char[] 배열에 파일 내용을 한 줄로 읽음
- char 은 문자 1개씩 읽는 문자타입임. 즉, char[10000]은 만 자의 문자를 한 배열에 담겠다는 뜻.
(4) path에 있는 파일을 char[] 크기만큼 읽어들여 담는다.
- 파일 내용이 10000자보다 많으면 루프를 돌려서 처리해야 한다.
(5) char[] 타입보다 String이 데이터 처리하기 편하기 때문에 String으로 변환한다.
- char[] 에는 엔터 대신 "\n"으로 표시되어 한 줄로 이어져 담겨있다. -> String에도 한 줄로 담겨진다.
(6) Stirng[] 에 한 줄의 String 값을 "\n"으로 split해서 각 방에 한 줄 씩 정보를 담는다.
(7) 그 중 0번방에 들어간 맨 윗 줄은 정보값의 인덱스이기 때문에 ","로 split해서 다른 String[]에 담는다.
(8) for 문을 돌리기 전에 값을 담을 ArrayList를 생성한다.
(9) 1번방부터 마지막방까지 루프를 돌며 ","로 split해서 Vo에 넣어 list에 넣는다.
- (정보 종류는 12개) ","로 split한 값을 담은 배열의 길이가 12개 이하이면 (== 공백) 무시한다.
(10) 인덱스 배열과 이하 정보값을 담은 리스트를 request에 담아 jsp로 보낸다.
- db에 넣고 싶으면 Dao 클래스를 만들어 Insert 메소드 만들기~
(11) 파일을 다 읽었으므로 입력스트림을 닫아준다.
(12) 이동할 jsp 페이지 주소를 return 한다.
총코드
package handler;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import csv.Vo;
// csv 파일 파싱해서 웹 페이지에 데이터를 출력
public class CsvHandler implements Handler {
@Override
public String process(HttpServletRequest request, HttpServletResponse response) {
// TODO Auto-generated method stub
// 웹에서 사용될 실제 주소로 변경
String path = request.getServletContext().getRealPath("/WEB-INF/files/a_utf8.csv");
try {
// 문자단위로 읽는 스트림 생성
FileReader fr = new FileReader(path);
// 파일에서 읽은 데이터 저장할 배열 생성
char[] buf = new char[10000]; // 한 줄로 읽어들일 값 크기 설정(전체데이터를 한 줄로 읽을것.)
// buf 크기만큼 파일에서 읽어서 buf에 저장
// 파일 내용이 10000자보다 많으면 루프를 돌려 처리해야 함.
fr.read(buf);
// char[] 보다 String이 데이터 처리하기 편함
String str = new String(buf); // 전체 데이터가 한 줄로 이어져 str에 담김
String[] data = str.split("\n"); // 엔터로 끊어서 방 하나에 한 줄씩 들어감
String[] titles = data[0].split(","); // 맨 윗줄을 ,로 끊어 title[] 방에 담음
ArrayList<Vo> list = new ArrayList<>();
for (int i = 1; i < data.length; i++) { // 1번 줄부터 마지막줄까지 읽어 list에 담음
String[] vals = data[i].split(",");
if(vals.length<12) {
continue;
}
list.add(new Vo(vals[0], vals[1], vals[2], vals[3], vals[4], vals[5],
vals[6], vals[7], vals[8], vals[9], vals[10], vals[11]));
}
// db에 넣고 싶으면 dao insert 호출해서 담기~
// jsp 페이지로 값 보내기
request.setAttribute("titles", titles);
request.setAttribute("list", list);
fr.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "/csv/list.jsp";
}
}
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>대전 열차 시간표</h3>
<table border="1">
<tr>
<c:forEach var="t" items="${titles}">
<th>${t }</th>
</c:forEach>
</tr>
<c:forEach var="vo" items="${list }">
<tr><td>${vo.arg1}</td><td>${vo.arg2}</td><td>${vo.arg3}</td><td>${vo.arg4}</td>
<td>${vo.arg5}</td><td>${vo.arg6}</td><td>${vo.arg7}</td><td>${vo.arg8}</td>
<td>${vo.arg9}</td><td>${vo.arg10}</td><td>${vo.arg11}</td><td>${vo.arg12}</td></tr>
</c:forEach>
</table>
</body>
</html>
2. JSON 파일


- 파일을 받으면 우선 데이터가 어떻게 들어가있는지 파악부터 해야 한다.
- 이 파일은 크게 보면 { } 로 객체임을 알 수 있음.
- 객체는 키:값 형태로 되어있음. 지금 같은 경우는
{ "주소" : { "주소" : [ { 키 : 값, 키 : 값 } , [ { 키 : 값, 키 : 값} ] , .... },
"주소" : { "주소" : [ { 키 : 값, 키 : 값 } , [ { 키 : 값, 키 : 값} ] , .... },
"주소" : { "주소" : [ { 키 : 값, 키 : 값 } , [ { 키 : 값, 키 : 값} ] , .... } }
- 값에 객체가 또 들어가있고.. 그 객체의 값에 배열이 들어가있고.. 그 배열 각각이 객체인.. 아주 복잡한 구조로 되어있다.
{
"http://data.ex.co.kr:80/link/serviceAreaFoods/B00099" : {
"http://data.ex.co.kr:80/link/def/salePrice" : [ {
"type" : "literal" ,
"value" : "₩7,000"
}
] ,
"http://data.ex.co.kr:80/link/def/batchMenu" : [ {
"type" : "literal" ,
"value" : "영양더덕산채비빔밥"
}
] ,
"http://data.ex.co.kr:80/link/def/serviceAreaName" : [ {
"type" : "literal" ,
"value" : "산청"
}
] ,
"http://data.ex.co.kr:80/link/def/routeName" : [ {
"type" : "literal" ,
"value" : "통영대전ㆍ중부고속도로"
}
] ,
"http://www.w3.org/2000/01/rdf-schema#label" : [ {
"type" : "literal" ,
"value" : "영양더덕산채비빔밥"
}
] ,
"http://data.ex.co.kr:80/link/def/direction" : [ {
"type" : "literal" ,
"value" : "통영"
}
]
}
,
.
.
.
"http://data.ex.co.kr:80/link/serviceAreaFoods/B00170" : {
"http://data.ex.co.kr:80/link/def/salePrice" : [ {
"type" : "literal" ,
"value" : "₩6,000"
}
] ,
"http://data.ex.co.kr:80/link/def/batchMenu" : [ {
"type" : "literal" ,
"value" : "베이컨 김치 볶음밥"
}
] ,
"http://data.ex.co.kr:80/link/def/serviceAreaName" : [ {
"type" : "literal" ,
"value" : "공주"
}
] ,
"http://data.ex.co.kr:80/link/def/routeName" : [ {
"type" : "literal" ,
"value" : "당진영덕고속도로"
}
] ,
"http://www.w3.org/2000/01/rdf-schema#label" : [ {
"type" : "literal" ,
"value" : "베이컨 김치 볶음밥"
}
] ,
"http://data.ex.co.kr:80/link/def/direction" : [ {
"type" : "literal" ,
"value" : "청원"
}
]
}
}
- 이때는 당황~하지~않고~ 반복되는 값이 무엇인지 파악하고 Vo를 만들어준다.
-- 어차피 반복문 돌릴게 눈에 훤하니까!
public class FoodVo {
private String label;
private String price;
private String area;
private String routeName;
private String direction;
}
- 그 다음엔 자연스럽게 데이터를 파싱할 핸들러 클래스를 만든다.
String path = request.getServletContext().getRealPath("/WEB-INF/files/serviceAreaFoods.json");
FileReader fr = new FileReader(path);
JSONParser parser = new JSONParser();
JSONObject obj = (JSONObject) parser.parse(fr);
Iterator iter = obj.keySet().iterator();
ArrayList<FoodVo> list = new ArrayList<>();
while(iter.hasNext()) {
String key = (String) iter.next();
// 음식 객체 하나를 꺼냄
JSONObject o = (JSONObject) obj.get(key);
// 음식명 추출
JSONArray arr = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/batchMenu");
JSONObject jsonlabel = (JSONObject) arr.get(0);
String label = (String) jsonlabel.get("value");
// 가격 추출
JSONArray arr2 = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/salePrice");
JSONObject jsonprice = (JSONObject) arr2.get(0);
String price = (String) jsonprice.get("value");
// 지역명 area 추출
JSONArray arr3 = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/serviceAreaName");
JSONObject jsonarea = (JSONObject) arr3.get(0);
String area = (String) jsonarea.get("value");
// 고속도로명 routeName 추출
JSONArray arr4 = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/routeName");
JSONObject jsonroute = (JSONObject) arr4.get(0);
String route = (String) jsonroute.get("value");
// 방향 direction 추출
JSONArray arr5 = (JSONArray) o.get( "http://data.ex.co.kr:80/link/def/direction");
JSONObject jsondirect = (JSONObject) arr5.get(0);
String direct = (String) jsondirect.get("value");
list.add(new FoodVo(label, price, area, route, direct));
}
request.setAttribute("list", list);
return "/json/list.jsp";
(1) 파라메터에 담은 경로를 웹에서 사용하는 실제 경로로 반환해 String path에 담는다.
-- 파라메터에 담은 경로는~ 파일을 저장한 폴더의 절대경로를 적으면 된다.
(2) JSON 파일도 문자 파일이기 때문에 FileReader로 입력 스트림을 열어준다.
JSONParser parser = new JSONParser();
JSONObject obj = (JSONObject) parser.parse(fr);(3) JSON을 파싱하기 위해 파서를 생성하고, path에 있는 파일을 파싱해 객체에 담는다.
- 위의 코드는 JSON.parse(txt) 와 같다.
- 해당 JSON 파일은 객체 타입이므로 {} JSONObject를 먼저 열어준 것!
(4) 객체의 키를 반복자로 읽어와 String에 담고, 그 키와 매칭된 값(음식 객체 하나)을 JSONObject에 담는다.
- 구조가 { 키 : 값{ 키 : 값[ {키:값, 키:값}], 키 : 값[{키:값, 키:값}] .... }}
{ "http://data.ex.co.kr:80/link/serviceAreaFoods/B00099" :
{ "http://data.ex.co.kr:80/link/def/salePrice" : [ { "type" : "literal" , "value" : "₩7,000" } ] , "http://data.ex.co.kr:80/link/def/batchMenu" : [ { "type" : "literal" , "value" : "영양더덕산채비빔밥" } ] ,
(5) 음식 객체는 { 주소 : [ { 키 : 값, "value" : 값 } ], ... } 이렇게 구성되어 있기때문에
1. 주소(키)와 매칭된 값(배열)을 JSONArray에 담는다.
2) 그 배열의 0번방(객체) 값을 JSONObject에 담는다.
3) 그 객체의 두 쌍 중에 "value"와 매칭돤 값을 String에 담는다.
----- 이 구조를 Vo 개수만큼 하고 Vo에 넣어 리스트에 담는다.
(6) 리스트를 jsp로 전달하기 위해 request에 담는다.
(7) 이동할 jsp 페이지 주소를 return한다.
총 코드
package handler;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.json.simple.JSONArray;
import org.json.simple.JSONObject;
import org.json.simple.parser.JSONParser;
import org.json.simple.parser.ParseException;
import json.FoodVo;
public class JsonHandler implements Handler {
@Override
public String process(HttpServletRequest request, HttpServletResponse response) {
// TODO Auto-generated method stub
String path = request.getServletContext().getRealPath("/WEB-INF/files/serviceAreaFoods.json");
try {
FileReader fr = new FileReader(path);
JSONParser parser = new JSONParser();
JSONObject obj = (JSONObject) parser.parse(fr); // json.parse(txt); 와 같음
Iterator iter = obj.keySet().iterator();
ArrayList<FoodVo> list = new ArrayList<>();
while(iter.hasNext()) {
String key = (String) iter.next();
// 음식 객체 하나를 꺼냄
JSONObject o = (JSONObject) obj.get(key);
// 음식명 추출
JSONArray arr = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/batchMenu");
JSONObject jsonlabel = (JSONObject) arr.get(0);
String label = (String) jsonlabel.get("value");
// 가격 추출
JSONArray arr2 = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/salePrice");
JSONObject jsonprice = (JSONObject) arr2.get(0);
String price = (String) jsonprice.get("value");
// 지역명 area 추출
JSONArray arr3 = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/serviceAreaName");
JSONObject jsonarea = (JSONObject) arr3.get(0);
String area = (String) jsonarea.get("value");
// 고속도로명 routeName 추출
JSONArray arr4 = (JSONArray) o.get("http://data.ex.co.kr:80/link/def/routeName");
JSONObject jsonroute = (JSONObject) arr4.get(0);
String route = (String) jsonroute.get("value");
// 방향 direction 추출
JSONArray arr5 = (JSONArray) o.get( "http://data.ex.co.kr:80/link/def/direction");
JSONObject jsondirect = (JSONObject) arr5.get(0);
String direct = (String) jsondirect.get("value");
list.add(new FoodVo(label, price, area, route, direct));
}
request.setAttribute("list", list);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "/json/list.jsp";
}
}<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>고속도로 휴게소 지역 음식 리스트</h3>
<table border="1">
<tr><th>음식명</th><th>가격</th><th>지역명</th><th>고속도로명</th><th>방향</th></tr>
<c:forEach var="vo" items="${list}">
<tr>
<td>${vo.label}</td><td>${vo.price}</td><td>${vo.area}</td><td>${vo.routeName}</td><td>${vo.direction}</td>
</tr>
</c:forEach>
</table>
</body>
</html>
3. XML 파일

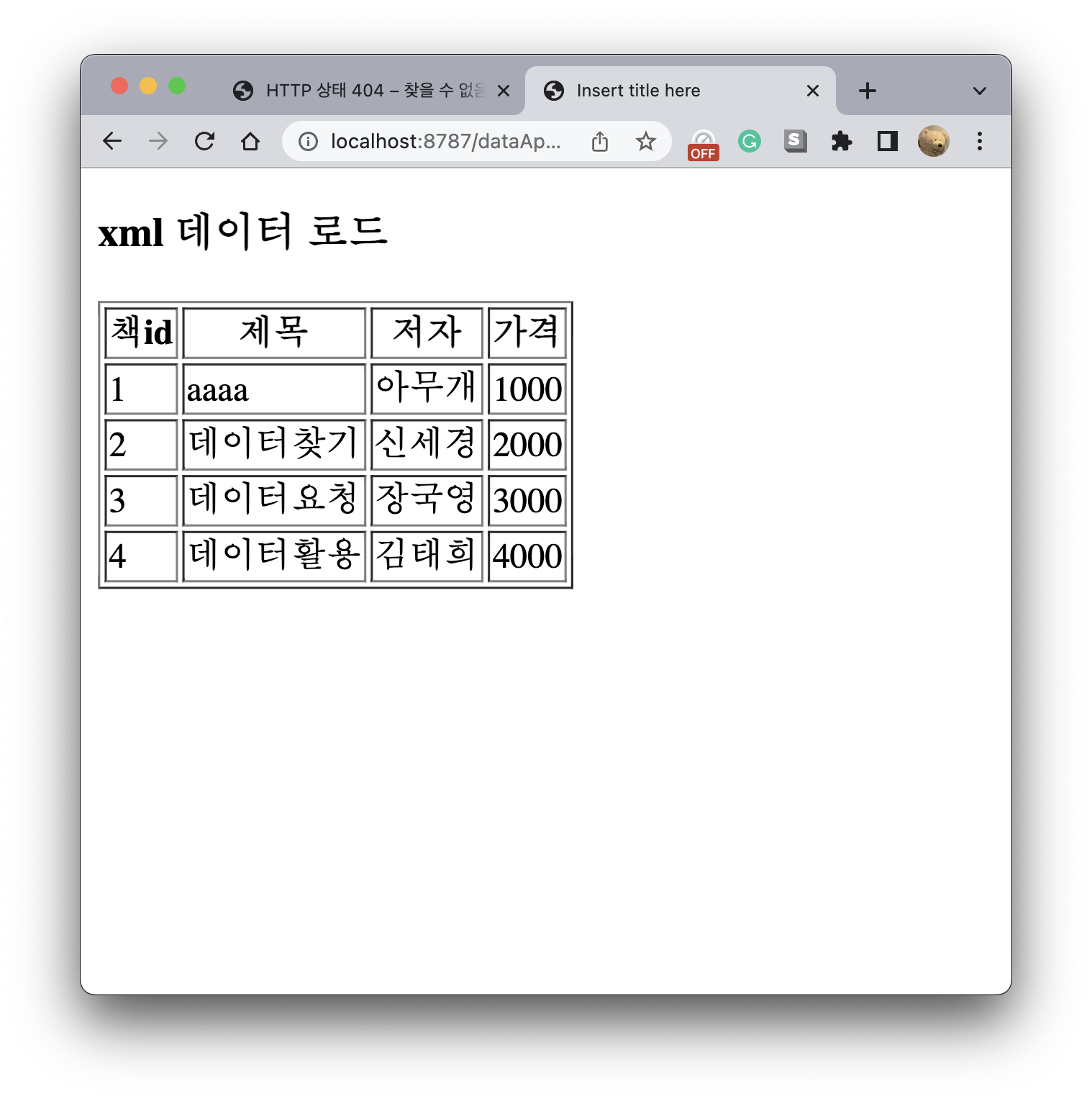
- XML 파일은 태그로 값이 나눠져 있다. --- 없는 태그를 정의해서 사용함.
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book>
<bookid>1</bookid>
<title>aaaa</title>
<author>아무개</author>
<price>1000</price>
</book>
<book>
<bookid>2</bookid>
<title>데이터찾기</title>
<author>신세경</author>
<price>2000</price>
</book>
<book>
<bookid>3</bookid>
<title>데이터요청</title>
<author>장국영</author>
<price>3000</price>
</book>
<book>
<bookid>4</bookid>
<title>데이터활용</title>
<author>김태희</author>
<price>4000</price>
</book>
</books>
- 파싱할 데이터 종류 만큼 Vo를 만들어 주고 -- 반복문 돌릴거니까~
public class BookVo {
private int num;
private String title;
private String author;
private int price;
}
- XML 파일을 파싱할 핸들러 클래스를 만들어준다.
String path = request.getServletContext().getRealPath("/WEB-INF/files/data.xml");
FileInputStream fi = new FileInputStream(path);
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(fi);
Element root = doc.getDocumentElement();
NodeList list = root.getChildNodes();
ArrayList<BookVo> datas = new ArrayList<>();
for (int i = 0; i < list.getLength(); i++) {
Node child = list.item(i);
NodeList infos = child.getChildNodes();
if (infos.getLength() == 0) { // 값 이외의 공백 제거
continue;
}
BookVo vo = new BookVo();
for (int j = 0; j < infos.getLength(); j++) {
Node info = infos.item(j);
String tagName = info.getNodeName();
switch (tagName) {
case "bookid":
vo.setNum(Integer.parseInt(info.getTextContent()));
break;
case "title":
vo.setTitle(info.getTextContent());
break;
case "author":
vo.setAuthor(info.getTextContent());
break;
case "price":
vo.setPrice(Integer.parseInt(info.getTextContent()));
break;
}
}
datas.add(vo);
}
request.setAttribute("datas", datas);
return "/xml/list.jsp";
(1) 파라메터에 담은 경로를 웹에서 사용하는 실제 경로로 반환해 String path에 담는다.
(2) CSV와 JSON이 문자 파일인 것과는 다르게 XML은 바이트 타입이라 FileInputStream으로 입력 스트림을 열어준다.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); // instance 생성
DocumentBuilder builder = factory.newDocumentBuilder(); // DocumentBuilder 객체 생성
Document doc = builder.parse(fi); // xml파싱(3) XML 파일은 DOM으로 파싱한다. DocumentBuilderFactory 클래스로 XML 문서에서 DOM 오브젝트 트리를 생성하는 parser를 얻을 수 있다. XML 파일에서 Dom document instance를 얻기 위해서는 DocumentBuilder 가 필요하다.
- 파일을 DocumentBuilder 로 파싱해서 Document에 넣어준다.
-- Document, Element, Node 모두 Dom 용어다.
여기서 Node와 Element의 차이점을 알아보자면,
- 돔은 Node의 계층구조로 이루어져 있고 Node는 텍스트, 주석, 요소 등 많은 유형을 포함한다.
- 요소는 Node 중 하나로, <p>, <body>, <div> 등 태그를 사용해 작성된 Node를 뜻한다.
Element root = doc.getDocumentElement();(4) root 요소를 뽑는다.
- root 요소란 최상단에 위치한 태그를 뜻한다. 이번 경우에는 <books> 이다.
즉, 이 태그 안의 값을 추출하겠다는 선전포고이므로 가장 바깥 태그를 먼저 불러오는 것.
NodeList list = root.getChildNodes();(5) 자식 노드를 추출한다. -- <book> 태그 모두 추출
- getChildNodes() 는 배열을 반환한다. 이 반환값을 NodeList에 넣는다.
- <book> 태그 사이의 정보값을 담을 BookVo 리스트도 생성해준다.
Node child = list.item(i);(5-1) for문을 NodeList 길이만큼 돌리면서 각 노드를 추출한다. -- <book></book> 사이 태그 모두 추출
- item(i) 는 NodeList에서 i번째 노드(i번째 <book>태그값)를 추출한다.
- 추출한 노드(<book>)의 자식 노드(<bookid>, <title>, <author>, <price>)들을 추출해서 NodeList에 담는다.
String tagName = info.getNodeName();
switch (tagName) {
case "bookid":
vo.setNum(Integer.parseInt(info.getTextContent()));
break;(5-2) for문을 NodeList 길이만큼 돌리면서 각 노드의 값을 추출한다. -- <bookid>, <title>, <author>, <price>의 사잇값
- getNodeName()으로 태그명을 추출해서 switch 문으로 반복문을 돌린다.
- getTextContent()로 태그 사이값을 추출해 vo에 담는다.
- (5) 에서 생성한 리스트에 vo를 담아준다.
- 이 리스트를 request에 담아 jsp 페이지로 전달한다.
- 이동할 jsp 주소를 return 한다.
총 코드
package handler;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import xml.BookVo;
public class XmlHandler implements Handler {
@Override
public String process(HttpServletRequest request, HttpServletResponse response) {
// TODO Auto-generated method stub
String path = request.getServletContext().getRealPath("/WEB-INF/files/data.xml");
try {
FileInputStream fi = new FileInputStream(path);
// DocumentBuilder 객체를 주는 factory 객체 생성
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// DocumentBuilder 객체 생성
DocumentBuilder builder = factory.newDocumentBuilder();
// xml파싱
Document doc = builder.parse(fi);
// 1. root 요소를 뽑는다. --> <books>
Element root = doc.getDocumentElement();
// 2. 자식 노드 추출 --> <book>태그 모두 추출
NodeList list = root.getChildNodes(); // 배열
ArrayList<BookVo> datas = new ArrayList<>();
for (int i = 0; i < list.getLength(); i++) {
Node child = list.item(i); // item(i) : nodelist에서 i번째 노드 추출 <book></book>
// <book>의 자식 노드들 추출 -- <bookid><title><author><price>
NodeList infos = child.getChildNodes();
if (infos.getLength() == 0) { // 값 이외의 공백 제거
continue;
}
BookVo vo = new BookVo();
for (int j = 0; j < infos.getLength(); j++) {
Node info = infos.item(j);
String tagName = info.getNodeName(); // getNodeName() : 태그명 추출
switch (tagName) {
case "bookid":
vo.setNum(Integer.parseInt(info.getTextContent()));
break;
case "title":
vo.setTitle(info.getTextContent());
break;
case "author":
vo.setAuthor(info.getTextContent());
break;
case "price":
vo.setPrice(Integer.parseInt(info.getTextContent()));
break;
}
// System.out.println(vo);
// String val = info.getTextContent(); // getTextContent() : 태그 사이 값
// System.out.println(tagName + " : " + val);
}
datas.add(vo);
}
request.setAttribute("datas", datas);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "/xml/list.jsp";
}
}<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>xml 데이터 로드</h3>
<table border = "1">
<tr><th>책id</th><th>제목</th><th>저자</th><th>가격</th></tr>
<c:forEach var="vo" items="${datas }">
<tr><td>${vo.num }</td><td>${vo.title }</td><td>${vo.author}</td><td>${vo.price}</td></tr>
</c:forEach>
</table>
</body>
</html>
https://intheham.tistory.com/79
[공공데이터] 2. URL로 불러와 파싱 (XML-기상청, 버스노선)
https://intheham.tistory.com/78 [공공데이터] 1. 다운받은 파일 파싱 (csv, json, xml) 공공데이터를 활용하는 방법에는 1. 공공데이터 사이트에서 파일을 다운받아 파싱 2. 온라인에서 바로 파싱 이번에는 1.
intheham.tistory.com